While the blogs aren’t updated very often, at some point they stopped working an just displayed a 502 error.
If I’m being honest, I have not idea what happened. The old setup was incredibly convoluted: a CDN in front of an Amazon ALB, in front of an oversized EC2 instance, using EFS for storage and an RDS instance for the database. The site was extremely behind on updates, and relied on a couple of separate custom plugins to properly render everything. At some point something in the chain stopped working.
Rather than debug it, I did something I’ve wanted to do for ages: I ripped everything apart and just moved it to a cheap shared hosting account at Dathorn. (Where “cheap” refers to price, not quality. I love Dathorn.) I kept Bunny in front as a CDN, in large part because the blog is basically static these days and because my prepaid $25 account will still last more than a year at current traffic levels. I even fixed (I think?) an issue where the fonts on my blog were being pulled from a defunct @font-face provider. Don’t expect a flurry of updates here, but with any luck, the site will stay online now!
I’m not sure yet if this is a good idea or not, nor if I want to pay for it long-term, but I’m playing with an experiment that I think is kind of neat. (But maybe I’m biased.)
Background
For a long time now, I’ve been using CloudFront to serve static assets (images, CSS, JS, etc.) on the blogs, and a few other sites I host. That content never changes, so I can offload it to a global Content Delivery Network. IMHO it’s win-win: visitors get a faster experience because most of those assets come from a server near them (they have a pretty extensive network), and I get my server alleviated from serving most images, so it’s only handling request for the blog pages themselves.
Except, serving images is easy; they’re just static files, and I’ve got plenty of bandwidth. What’s hard is serving blog pages: they’re dynamically-generated, and involve database queries, parsing templates, and so forth… Easily 100ms or more, even when things go well. What I’d really like is to cache those files, and just remove them from cache when something changes. And I’ve actually had that in place for a while now, using varnish in front of the blogs. It’s worked very well; more than 90% of visits are served out of cache. (And a decent bit of the 10% that miss are things that can’t be cached, like form POSTs.) It alleviates backend load, and makes the site much faster when cache hits occur, which is most of the time.
But doing this requires a lot of control over the cache, because I need to be able to quickly invalidate the cache. CloudFront doesn’t make that easy, and they also don’t support IPv6. What I really wanted to do was run varnish on multiple servers around the world myself. But directing people to the closest server isn’t easy. Or, at least, that’s what I thought.
Amazon’s Latency-Based Routing
Amazon (more specifically, AWS) has supported latency-based routing for a while now. If you run instances in, say, Amazon’s Virginia/DC (us-east-1) region and in their Ireland (eu-west-1) data centers, you can set up LBR records for a domain to point to both, and they’ll answer DNS queries for whichever IP address is closer to the user (well, the user’s DNS server).
It turns out that, although the latency is in reference to AWS data centers, your IPs don’t actually have to point to data centers.
So I set up the following:
NYC (at Digital Ocean), mapped to us-east-1 (AWS’s DC/Virginia region)
Frankfurt, Germany (at Vultr), mapped to eu-central-1 (AWS’s Frankfurt region)
Los Angeles (at Vultr), mapped to us-west-1 (AWS’s “N. California” region)
Singapore (at Digital Ocean), mapped to ap-southeast-1 (AWS’s Singapore region)
The locations aren’t quite 1:1, but what I realized is that it doesn’t actually matter. Los Angeles isn’t exactly Northern California, but the latency is insignificant—and the alternative was all the traffic going to Boston, so it’s a major improvement.
Doing this in DNS isn’t perfect, either: if you are in Japan and use a DNS server in Kansas, you’re going to get records as if you’re in Kansas. But that’s insane and you shouldn’t do it, but again, it doesn’t entirely matter. You’re generally going to get routed to the closest location, and when you don’t, it’s not really a big deal. Worst case, you see perhaps 300ms latency.
Purging
It turns out that there’s a Multi-Varnish HTTP Purge plugin, which seems to work. The downside is that it’s slow: not because of anything wrong with the plugin, but because, whenever a page changes, WordPress now has to make connections to four servers across the planet.
I want to hack together a little API to accept purge requests and return immediately, and then execute them in the background, and in parallel. (And why not log the time it takes to return in statsd?)
Debugging, and future ideas
I added a little bit of VCL so that /EDGE_LOCATION will return a page showing your current location.
I think I’m going to leave things this way for a while and see how things go. I don’t really need a global CDN in front of my site, but with Vultr and Digital Ocean both having instances in the $5-10 range, it’s fairly cheap to experiment with for a while.
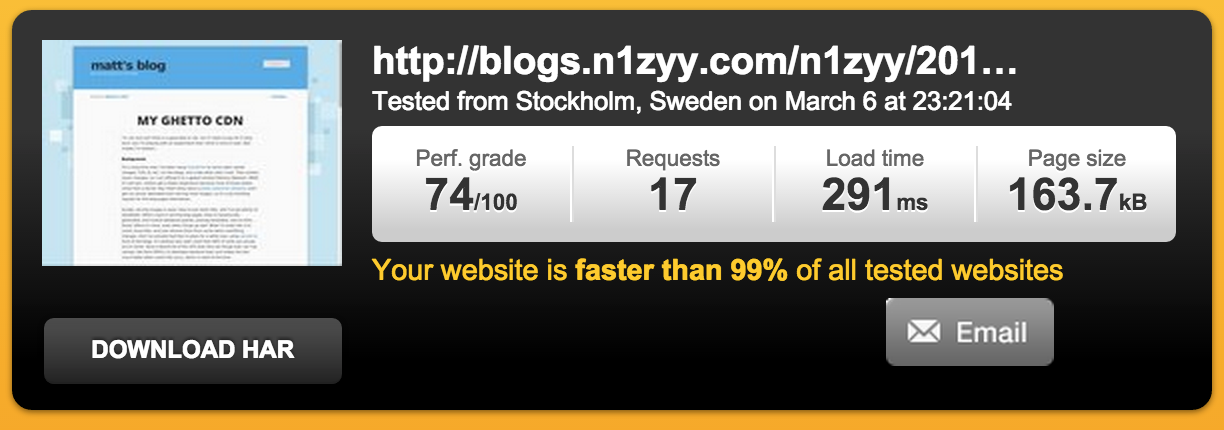
Page loaded in 291ms: after fetching all images and stylesheets. I’ll take that anywhere! But for my site, loaded in Stockholm? I’m really pleased with that.
I’ve mentioned before about how the sync_binlog setting in MySQL can be especially slow on ext3. Of course, I wasn’t the first to discover this; the MySQL Performance Blog mentioned it months ago.
I was reading through some of the slides I mentioned in my last post, and remembered that I’d left sync_binlog off on an in-house replicated slave. You’re able to set it on the fly, so a quick set global sync_binlog=1 was all it took to ensure we flushed everything to disk.
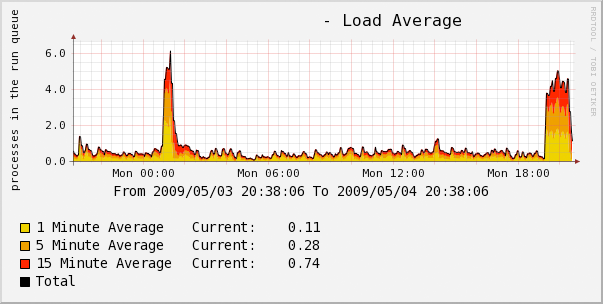
A while later I blogged about dstat and thought to run it on the in-house MySQL slave. I was confused to notice that the CPU was about 50% idle, 50% “wai” (I/O wait). For a box that’s just replaying INSERTs from production, that’s really bad. Below is a graph of load on the system. Care to guess when I enabled sync_binlog?
Performace with and without sync_binlog enabled
Disk I/O does roughly the same thing, but it’s less pronounced, “only” doubling in volume. But the difference is still pretty insane!
I think part of the thing I love about MySQL is the same thing I love about Firefox and Thunderbird. Even though I sometimes wonder if there are databases that would work better than MySQL or have fewer bugs, MySQL has an incredibly rich community that’s home to myriad fascinating projects.
I’ve looked into MySQL Proxy at work a bit, and found it pretty interesting, but it’s still considered alpha-level code, and we don’t really need a proxy in front of our database right now.
I’m not even going to pretend that the links that follow are all things I’ve just found on my own. They’re inspired from this Xapbr post, with Xapbr being a blog run by one of the top guys at Percona, and Percona being a well-known MySQL consulting firm, perhaps best known for the O’Reilly High Performance MySQL book. (A must-read even for people who aren’t full-time DBAs!)
It turns out that MySQL Proxy has a competitor, Dormando’s Proxy for MySQL, better known as dpm. It’s a BSD-licensed proxy created by SixApart’s DBA. (SixApart used to own LiveJournal, which is well-known for releasing memcached to the community.) Given that I’ve worked with neither dpm nor MySQL Proxy, I’m not able to comment on the merits of either, but it’s a handy link to have.
I’m also interested in the Tungsten Replicator, an Open Source project providing (emphasis mine) “database-neutral master/slave replication,” which was interesting enough to keep me reading past the words “JDK” and “Ant,” which are technical terms meaning “bloat” and “memory leaks.” (I kid… Sort of.) It looks like the project is mostly MySQL-centric right now, but capable of replicating MySQL databases into Oracle. (But apparently not the other way, probably since Oracle binlogs aren’t as publicly-documented as MySQL’s.)
And then there’s WaffleGrid, a project using memcache as an L2 cache. That is, MySQL will first look in its own caches, but in the event of a cache miss, will check memcache before turning to disk. It looks like it gives stellar results, even though it’s one of those things that seems kind of wrong. (You’d think that, if you’re adding memory to better cache your database, you’d want to put it in the MySQL machine, and if you needed to scale to a cluster of memcache boxes, you might be better off spreading the load around several MySQL boxes… But at the same time, clustering isn’t something MySQL excels at right now.)
Drizzle is “a lightweight SQL database for [the] cloud and web,” which is forked from MySQL 6. (And for those of you scratching your heads: yes, I said version 6. Yes, 5.1 is the latest release branch.) There are some big names working on Drizzle, and besides “the cloud,” they talk a lot about “massive concurrency,” which is something that should be of interest even to people running more traditional databases.
And, of course, there’s Percona’s XtraDB engine for MySQL, a significant overhaul to InnoDB. It seems a bit of a young technology for production environments, and yet it seems like it’s production environments where it would have the best impact.
This is only tangentially related to MySQL, but I’ve seen Sphinx mentioned in at least three distinct places today, a SQL-based fulltext search index. I’d be curious in seeing how it compares with Lucene.
UNIX systems have their “swap” partition, a disk partition where unused stuff in RAM is “swapped out” to disk to make room for newer stuff in RAM. Of course, no hard drive is as fast as RAM, so you obviously want lots of RAM so you never touch swap. Windows has the same concept but calls it a paging file.
But what if your disk was as fast as RAM? I remain fascinated by OCZ’s new 64GB SSD, which has an almost-zero seek time, and throughput rivaling the best of hard drives. (Though I’m yet to read any actual reviews, as it seems to have still not quite shipped.) I suspect that, given factors like the direct bus between your CPU and RAM, and all the work on boosting RAM “speeds,” a solid-state disk wouldn’t literally be as fast as RAM. But I also think that the difference between having more RAM and “swapping out” to SSD would be somewhat negligible.
I think it’d be interesting to test the extent of this… Plunk an SSD (one with high throughput!) into a system, and run it on as little memory as you can. (Though I think you’d be hard-pressed to find anything less than 256MB DIMMs these days, and even those might be hard to find? I wonder if Linux has a facility for deliberately overlooking a quantity of its RAM?) And with that set up, go crazy with stuff to ensure that you’re using several gigs of “memory.”
We can sit around all day and measure bus speeds and Mbps throughput and latency and seek time, but I think the only meaningful measure would be to try this and see how it feels. I have a hunch that it wouldn’t be that big of a slowdown (compared to RAM), but that the biggest problem would be ensuring your SSD was on a separate controller/ bus/ channel, so you didn’t obliterate your hard drive performance. While it’s easy to get an affordable system with a couple gigs of RAM now, RAM remains expensive if you need a decent amount of it. Buying a system with 64GB of RAM would still be extraordinarily expensive, but with a 64GB SSD for under $300, you could imitate it fairly well.
I’d posted before about my interest in picking up a low-capacity SSD card for my laptop, to drastically speed up disk access. (This actually has nothing to do with my recent posts about slow hard drives…)
Newegg seems to have a 64 GB SSD, 2.5″ SATA disk for $240 after rebate. Interestingly, from the specs, it seems as if not only are the seek times nill (on account of being solid-state), but the throughput exceeds that of your average hard disk. It won’t be released for four days, however. (Found via FatWallet, which also links to a review here.)
For those who aren’t major geeks, SSD is short for “solid-state disk.” Your ordinary hard drive is a bunch of spinning platters, whereas solid-state is the technology you see in a USB thumb drive or the like: no moving parts. The major benefit of SSDs thus far has been seek time: with a normal hard disk, the disk has to find the right spot on the disk and read it. Seek times average 8-10ms on most normal drives, but that adds up quickly with fragmentation or concurrent I/O. With an SSD, there are no moving parts, so “seek time” is pretty much non-existent: files are ready instantly. Early SSDs seemed to not be capable of moving as much data (in terms of MB/sec), though, meaing that SSDs were great for lots of small “random” access, but not so hot for handling big, contiguous files. Now, it’s looking as if OCZ has made SSDs kick butt over normal hard drives, and somehow offered the product at a fraction of what it normally costs. (This 64GB SSD is more normally-priced, to give you an idea of why they haven’t caught on so quickly.)
Incidentally, today I came across deals on two different notebooks for about $700, both of which have 4GB RAM, but 1280×800-pixel screens. The RAM is incredible, as are most of the other specs (though it’s 5400RPM drives), but I think you can do much better on the resolution.
I think I’ve alluded earlier to the fact that I’ve been trying to speed up some systems at home, and how some of them are really slow. (I’m starting to suspect Norton, actually, but more on that when I find out more.)
I just came across this spiffy application, which will write and then read a test file to measure disk performance. My laptop gets 27.1 MB/sec. (sequential) write, 41 MB/sec. sequential read, and 29.9 MB/sec. random reads. This was on a 1GB file; it wanted to do a ~4 GB file, but I really didn’t feel like spending the time. I suspect the goal is to make sure that it’s not being “fooled” by caching, but I figured 1GB was sufficient for that. Some of the results show read speeds of 600+ MB/sec., which is most definitely coming from cache. (That said, this is a more “real-life” test… Just don’t think you have a hard drive that does 800MB/sec. reads!)
From my “Random ideas I wish I had the resources to try out…” file…
The way the “pretty big” sites work is that they have a cluster of servers… A few are database servers, many are webservers, and a few are front-end caches. The theory is that the webservers do the ‘heavy lifting’ to generate a page… But many pages, such as the main page of the news, Wikipedia, or even these blogs, don’t need to be generated every time. The main page only updates every now and then. So you have a caching server, which basically handles all of the connections. If the page is in cache (and still valid), it’s served right then and there. If the page isn’t in cache, it will get the page from the backend servers and serve it up, and then add it to the cache.
The way the “really big” sites work is that they have many data centers across the country and your browser hits the closest one. This enhances load times and adds in redundancy (data centers do periodically go offline: The Planet did it just last week when a transformer inside blew up and the fire marshalls made them shut down all the generators.). Depending on whether they’re filthy rich or not, they’ll either use GeoIP-based DNS, or have elaborate routing going on. Many companies offer these services, by the way. It’s called CDN, or a Contribution Distribution Network. Akamai is the most obvious one, though you’ve probably used LimeLight before, too, along with some other less-prominent ones.
I’ve been toying with SilverStripe a bit, which is very spiffy, but it has one fatal flaw in my mind: its out-of-box performance is atrocious. I was testing it in a VPS I haven’t used before, so I don’t have a good frame of reference, but I got between 4 and 6 pages/second under benchmarking. That was after I turned on MySQL query caching and installed APC. Of course, I was using SilverStripe to build pages that would probably stay unchanged for weeks at a time. The 4-6 pages/second is similar to how WordPress behaved before I worked on optimizing it. For what it’s worth, static content (that is, stuff that doesn’t require talking to databases and running code) can handle 300-1000 pages/second on my server as some benchmarks I did demonstrated.
There were two main ways to enhance SilverStripe’s performance that I thought of. (Well, a third option, too: realize that no one will visit my SilverStripe site and leave it as-is. But that’s no fun.) The first is to ‘fix’ Silverstripe itself. With WordPress, I tweaked MySQL and set up APC (which gave a bigger boost than with SilverStripe, but still not a huge gain). But then I ended up coding the main page from scratch, and it uses memcache to store the generated page in RAM for a period of time. Instantly, benchmarking showed that I could handle hundreds of pages a second on the meager hardware I’m hosted on. (Soon to change…)
The other option, and one that may actually be preferable, is to just run the software normally, but stick it behind a cache. This might not be an instant fix, as I’m guessing the generated pages are tagged to not allow caching, but that can be fixed. (Aside: people seem to love setting huge expiry times for cached data, like having it cached for an hour. The main page here caches data for 30 seconds, which means that, worst case, the backend would be handling two pages a minute. Although if there were a network involved, I might bump it up or add a way to selectively purge pages from the cache.) squid is the most commonly-used one, but I’ve also heard interesting things about varnish, which was tailor-made for this purpose and is supposed to be a lot more efficient. There’s also pound, which seems interesting, but doesn’t cache on its own. varnish doesn’t yet support gzip compression of pages, which I think would be a major boost in throughput. (Although at the cost of server resources, of course… Unless you could get it working with a hardware gzip card!)
But then I started thinking… That caching frontend doesn’t have to be local! Pick up a machine in another data center as a ‘reverse proxy’ for your site. Viewers hit that, and it will keep an updated page in its cache. Pick a server up when someone’s having a sale and set it up.
But then, you can take it one step further, and pick up boxes to act as your caches in multiple data centers. One on the East Coast, one in the South, one on the West Coast, and one in Europe. (Or whatever your needs call for.) Use PowerDNS with GeoIP to direct viewers to the closest cache. (Indeed, this is what Wikipedia does: they have servers in Florida, the Netherlands, and Korea… DNS hands out the closest server based on where your IP is registered.) You can also keep DNS records with a fairly short TTL, so if one of the cache servers goes offline, you can just pull it from the pool and it’ll stop receiving traffic. You can also use the cache nodes themselves as DNS servers, to help make sure DNS is highly redundant.
It seems to me that it’d be a fairly promising idea, although I think there are some potential kinks you’d have to work out. (Given that you’ll probably have 20-100ms latency in retreiving cache misses, do you set a longer cache duration? But then, do you have to wait an hour for your urgent change to get pushed out? Can you flush only one item from the cache? What about uncacheable content, such as when users have to log in? How do you monitor many nodes to make sure they’re serving the right data? Will ISPs obey your DNS’s TTL records? Most of these things have obvious solutions, really, but the point is that it’s not an off-the-shelf solution, but something you’d have to mold to fit your exact setup.)
Aside: I’d like to put nginx, lighttpd, and Apache in a face-off. I’m reading good things about nginx.
It’s no secret that gzip is handy on UNIX systems for compressing files. But what I hadn’t really considered before is that you don’t have to create a huge file and thengzip it. You can simply pipe output through it and have it compressed on the fly.
That backed up all the databases on this machine and compressed them. (It’s a 31MB file, but that’s nothing when you realize that one of my databases is about 90MB in size, and I have plenty others at 10-20MB each.)
I’ve alluded before to using gzip compression on webserver. HTML is very compressible, so servers moving tremendous amounts of text/HTML would see a major reduction in bandwidth. (Images and such would not see much of a benefit, as they’re already compressed.)
As an example, I downloaded the main page of Wikipedia, retrieving only the HTML and none of the supporting elements (graphics, stylesheets, external JavaScript). It’s 53,190 bytes. (This, frankly, isn’t a lot.) After running it through “gzip -9” (strongest compression), it’s 13,512 bytes, just shy of a 75% reduction in size.
There are a few problems with gzip, though:
Not all clients support it. Although frankly, I think most do. This isn’t a huge deal, though, as the client and server “negotiate” the content encoding, so it’ll only be used if it’s supported.
Not all servers support it. I don’t believe IIS supports it at all, although I could be wrong. Apache/PHP will merrily do it, but it has to be enabled, which means that lazy server admins won’t turn it on.
Although it really shouldn’t work that way, it looks to me as if it will ‘buffer’ the whole page then compress it, then send it. (gzip does support ‘streaming’ compression, just working in blocks.) Thus if you have a page that’s slow to load (e.g., it runs complex database queries that can’t be cached), it will appear even worse: users will get a blank page and then it will suddenly appear in front of them.
There’s overhead involved, so it looks like some admins keep it off due to server load. (Aside: it looks like Wikipedia compresses everything, even dynamically-generated content.)
But I’ve come across something interesting… A Hardware gzip Compression Card, apparently capable of handling 3 Gbits/second. I can’t find it for sale anywhere, nor a price mentioned, but I think it would be interesting to set up a sort of squid proxy that would sit between clients and the back-end servers, seamlessly compressing outgoing content to save bandwidth.