This month’s bandwidth:
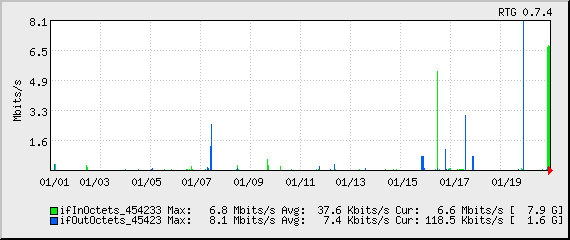
Tonight’s bandwidth (since start of backup):
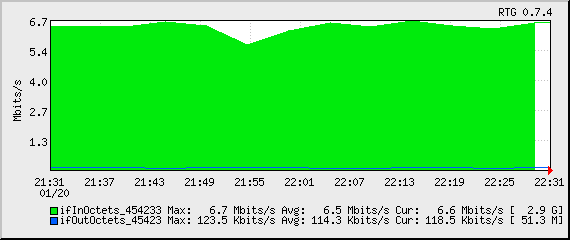
This month’s bandwidth:
Tonight’s bandwidth (since start of backup):
Sun bought MySQL.
Also, Sun’s CEO {has a blog, doesn’t know how to resize images other than changing the HTML attributes}.
Remember back when they were a little below $5 a share and I said I thought they were going somewhere?
Next time I’m putting my money where my mouth is. They closed at $15.92 a share on Friday.
Of course, some are wondering whether this was a good buy. Not necessarily whether MySQL is good (it’s perhaps the most widely-used database in the world), but whether it makes sense to pay a billion dollars for it, when it’s (1) primarily an OpenSource product, and (2) going to take something like 20 years of revenues to break even. While I don’t quite buy the bit about it being a conspiracy with Oracle to kill the project, you should check out the page they link to, Sun’s list of acquisitions. It’s so bad that Sun appears to have a photograph of a dumpster with the Sun logo on it. (Okay, it’s a shipping crate. But it doesn’t make a ton of sense, and you have to grant that it looks a little bit like a dumpster.) It reminds me of when Sun bought Cobalt for $2 billion, and Cobalt went belly-up shortly thereafter. (I still think RaQs could be hot sellers today, by the way, if they were still being made. To take a company doing incredibly well and have it go belly-up in under a year takes some incredible mis-management.)
The real geeks in the room already know what the root zone file is, but for those of you with lives… DNS (Domain Name Service) is the service that transforms names (blogs.n1zyy.com) into IPs (72.36.178.234). DNS is hierarchical: as a good analogy, think of there being a folder called “.com,” with entries for things like “amazon” and “n1zyy” (for amazon.com and n1zyy.com, two sites of very comparable importance.) Within the amazon ‘folder’ is a “www,” and within “n1zyy” is a “blogs,” for example. A domain name is really ‘backwards,’ then: if it were a folder on your hard drive, it would be something like C:.com.n1zyyblogs.
Of course, this is all spread out amongst many servers across the world. When you go to connect to blogs.n1zyy.com, you first need to find out how to query the .com nameservers. The root servers are the ones that give you this answer: they contain a mapping of what nameservers are responsible for each top-level domain (TLD), like .com, .org, and .uk.
So you get your answer for what nameservers process .com requests, and go to one of them, asking what nameserver is responsible for n1zyy.com. You get your answer and ask that nameserver who’s responsible for blogs.n1zyy.com, and finally get the IP your computer needs to connect to. And, for good measure, it probably gets cached, so that the next time you visit the site, you don’t have to go through the overhead of doing all those lookups again. (Of course, this all happens in the blink of an eye, behind the scenes.)
Anyway! The root zone file is the file that the root servers have, which spells out which nameservers handle which top-level domains.
Yours truly found the root zone file (it’s no big secret) and wrote a page displaying its contents, and a flag denoting the country of each of the nameservers. The one thing I don’t do is map each of the top-level domains to their respective country, since, in many cases, I don’t have the foggiest clue.
What’s interesting to note is that a lot of the data is just downright bizarre. Cuba has six nameservers for .cu. One is in Cuba, one in the Netherlands, and four are in the US. Fiji (.fj) has its first two nameservers… at berkeley.edu. American universities hosting foreign countries’ nameservers, however bizarre, isn’t new. .co (Colombia) has its first nameservers in Colombia (at a university there), but also has NYU and Columbia University (I think they did that just for the humor of Columbia hosting Colombia).
In other news, it turns out that there’s a list of country-to-ccTLD (Country-Code Top Level Domain) mappings. I’m going to work on incorporating this data… Maybe I can even pair it up with my IPGeo page with IP allocations per country…
Culled from recent news, here are some things that have occurred that I can find absolutely no excuse for having happened:
I won’t lie–I love OpenBSD’s spamd. In a nutshell, it’s a ‘fake’ mailserver. You set your firewall up to connect obvious spammers to talk to this instead of your real mailserver. It talks to them extremely slowly (1B/sec), which keeps them tied up for quite some time. (As an added bonus, it throws them an error at the end.)
One thing that really gets under my skin is bots (and malicious users) probing for URLs on the server that don’t exist. I get a lot of hits for /forum, /phpbb, /forums, /awstats… What they’re doing is probing for possible (very) outdated scripts that have holes allowing remote code execution.
It finally hit me: it’s really not that hard to build the same thing for HTTP. thttpd already supports throttling. (Note that its throttling had a more sane use in mind: limiting overall bandwidth to a specific URL, not messing with spammers and people pulling exploits, so it’s not exactly what we want, but it’ll do.)
Then you need a large file. I downloaded a lengthy novel from Project Gutenberg. It’s about 700 kB as uncompressed text. I could get much bigger files, yes. But 700 kB is plenty. More on this later.
It’s also helpful to use Apache and mod_rewrite on your ‘real’ server. You can work around it if you have to.
Set up your /etc/thttpd/throttle.conf:
** 16
Note that, for normal uses, this is terrible. This rule effectively says, “Limit the total server (**) to 16 (bytes per second).” By comparison, a 56K dialup line is about 7,000 bytes per second (or 56,000 bits per second).
Rudimentary tests show that having one client downloading a 700 kB file at 16B/sec places pretty much no load on the server (load average remained 0.00, and thttpd doesn’t even show up in the section of top that I can see), so I’m not concerned about overhead.
You can also set up your thttpd.conf as needed. No specific requirements there. Start it up with something like thttpd -C /etc/thttpd/thttpd.conf -d /var/www/maintenance/htdocs/slow -t /etc/thttpd/throttle.conf (obviously, substituting your own directories and file names! Note that the /slow is just the directory I have it serving out of, not any specific naming convention.)
Now what we need to do is start getting some of our mischievous URL-probers into this. I use some mod_rewrite rules on my ‘real’ Apache server:
# Weed out some more evil-doers RewriteRule ^forum(.*)$ http://ttwagner.com:8080/20417.txt [NC,L] RewriteRule ^phpbb(.*)$ http://ttwagner.com:8080/20417.txt [NC,L] RewriteRule ^badbots(.*)$ http://ttwagner.com:8080/20417.txt [NC,L] RewriteRule ^awstats(.*)$ http://ttwagner.com:8080/20417.txt [NC,L]
In a nutshell, I redirect any requests starting with “forum,” “phpbb,” “badbots,” or “awstats” to an enormous text file. I’m not sure if escaping the colon is strictly necessary, but it has the added benefit of ‘breaking’ the link when pasted, say, here: I don’t want anyone getting caught up in this unless they’re triggering it. I tend each with (.*), essentially matching everything. You may or may not see this as desirable. I like it, since /forum and /forums are both requested, and so forth. You could take that out if necessary. The [NC,L] is also useful in terms of, well, making anything work.
I want to watch and see whether anyone gets caught up in this. Since it’s technically passing the request to a different webserver (thttpd), it has to tell the client to connect to that, as opposed to seamlessly serving it up. I don’t know if the bots are smart (dumb?) enough to follow these redirects or not.
Note that /badbots doesn’t really exist. I inserted it into my robots.txt file, having heard that some ‘bad ‘bots (looking for spam, etc.) crawl any directory you tell them not to. I wondered if this was accurate.
The ending is quite anticlimactic: we wait not-so-patiently to see what ends up in the logfile.
So my new policy is to keep spam ‘on file’ for three days. It’s filed away as spam so no one sees it, but it’s good for analysis and such, to protect against future spam. Several times a day, I run a little script to delete spam older than three days and optimize the tables, to keep things running fast.
So this table is particularly telling of the spam problem. Akismet is catching just about all of it, so it’s not a big problem for me per se, but the fact remains that, with three days of spam and something like nine months of legitimate comments, spam accounts for right around two-thirds of all comments on my blog. Wow-a-wee-wow!
Tonight I ate at a small restaurant in Amherst, and had the most delicious bottle of root beer ever. Called Virgil’s, it’s kind of hard to put my finger on what makes it so good. As I read the bottle for clues, I noticed that they were publicly traded. I thought this was strange, given that I’ve never even heard of them.
But indeed, they’re REED on the NASDAQ. And they closed out 2006 with a -21% profit margin and a -124% return on average equity. The “past” quarter (ended September ’07–newer results aren’t in) was exceptionally bad, with an almost -40% margin. But as I dug deeper, I realized that this wasn’t such a bad thing. They retired (paid) $1.6 million of debt, after a capital infusion of several millions (“paid-in capital”). They still had an outstanding $8.24 million deficit, but it’s maybe a good sign.
I’d still have reservations, though: the past quarter saw $3.88 million revenues, generated with $5.4 million of operating expense. They’ve got to find a way to either cut these costs, or grow revenues. (Or, preferably, do both!) Recent announcements suggest that Reed has found some new distributors and supermarkets to carry their chain, which may be what they need to come into the black.
And after all of this, I realized something: I set out to see if I could buy their soda online. And I ended up scrutinizing the company’s financials.
I tend to border on obsessive-compulsive. I wax the wheels on my car. I’m still not happy with the enormous performance gains I’ve gotten by tuning my WordPress setup to move from 4 to 400 (dynamic) pages per second.
So it stands to reason that how I clean my desk is… unique. The problem is that the desk is synthetic wood, so there exist a total of zero cleaning products that work on it. Using something like Windex cleans it but leaves it looking even more dull. And don’t even think about using a wood cleaner. I used Pledge once. It looked great, but it remained slippery for about a week. The Pledge is apparently supposed to sink into the wood. This is somewhat difficult when the desk isn’t made of wood, so you instead get an incredibly slick, oily desk.
I think I finally found the key, though: car wax. You clean with one of the many cleaners just to get junk off of it–I used Simple Green, but Windex would work just as well. And then you pour liquid car wax on and apply it with a cloth as if you were applying it to your car. Wait a while for it to dry, and wipe the white hazy stuff off. The result is a high sheen. It didn’t do as well as I’d like with filling in the scratches, but it looks much better overall.
I admit it: I’m a total dork. I just waxed my desk. But… It works.
It’s time! I’m going to go grab some lunch, but then I’m going out to cast my vote, run a couple errands, and then spend the rest of the day on Get Out The Vote activities. When the polls close at 8, I’ll breath a sigh of relief that I can sit down, but I think my nerves will be shot, too, as I go somewhere with my fellow supporters to watch the results come in.
New Hampshire residents, don’t forget to vote!